
Understanding Daemons

In this article, we’ll take a closer look at daemons. We’ll understand exactly what they are, how they’re implemented, and the scope of their responsibility.
Overview
Simply put, a daemon (pronounced dee-mon) is an intentionally orphaned background process. Additionally, daemons are detached from the terminal in which they’re spawned, operate without user interaction, and are descendants of the system’s init process.
Daemons will silently wait in the background for specific events to occur or conditions to be met before executing.
At boot time, Linux will start the init process (init is itself a daemon) which will serve as the parent of all processes, and assign it PID 1 (process identification number). It’s important to mention that the init function is a special process that is not attached to any terminal.
After the boot sequence is complete, Linux will start up any previously declared daemons. These will be created through a series of fork() and exit() commands which will intentionally create an orphaned process that will eventually be adopted by the init process – more on this soon.
Use Cases
Conventionally, daemon process names end with the letter “d”. If you’re interested in seeing all daemons installed on your Linux machine, use this command:
service --status-all
You’ve certainly encountered daemons whether you were aware of them or not:
- A web server is simply a process that runs continuously in the background waiting to process and respond to HTTP requests (http daemon)
- sshd is the dameon responsible for SSH operations
- “MAILURE_DEMON” is a daemon that notifies the sender of invalid email recipients
- Monitoring hardware activity like hard drive health
- cron jobs
Implementation
We’ll take a look at the code to create a daemon shortly, but let’s establish some basics first.
Calling the fork() function creates a new process referred to as the child process. The child process runs in parallel with the process that triggered the fork() (the parent process).
A child process shares the same program counter and CPU registers as its parent. So, when a new child process is created, both the child and parent processes will execute the next instruction after the fork() call in parallel.
Here’s a simple example from Michigan Tech:
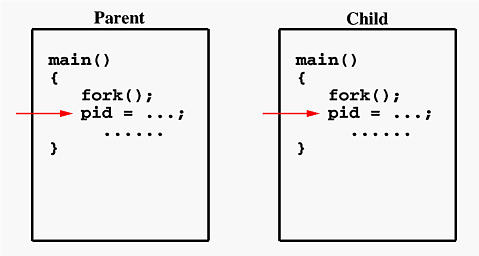
After fork(), both the parent and the child processes execute the following code in parallel.
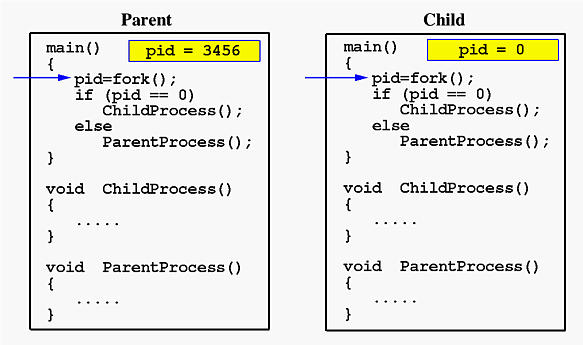
You can also make their execution paths differ if desired. If the fork() call succeeds, the PID of the child process is returned in the parent, and 0 is returned in the child.
In order to create a daemon, we’ll fork() to create a child process and then exit() the parent. This, as previously mentioned, will purposefully create an orphaned process that will be adopted by init.
Our new daemon is now free to sit silently in the background outside of any terminal and perform its task.
While this is a practical understanding, the actual implementation is a bit more nuanced.
We’ll need to make sure to do the following:
- Close all open file descriptors
- Change the working directory
- Separate from the terminal and ignore I/O signals
- Disassociate from the process group and control terminal
- Don’t reacquire a control terminal
- Reset the file access creation mask
The following implementation is inspired by Pascal Werkl’s work. I’ve added additional documentation to make it more approachable for someone that is unfamiliar with C and/or Linux systems. I encourage you to checkout the original code here.
Understanding the double fork()
Let’s try and understand why we need 2 fork() calls in the code above.
When we run this program in the terminal, several environmental settings – specifically the shell we’re working in – are replicated to our child process. So, we’ll need to disassociate our daemon from its spawning terminal.
That’s why we call setsid() and create our own independent session for the child process.
However, in doing so, this child process will be in its own session and process group and therefore it’ll be its own session leader. The main takeaway here is that there is potential for the session leader to reacquire a terminal later on (i..e. if say the user were to open up another terminal).
We don’t want that. Remember, we want to be completely independent of the terminal and any user input.
By calling fork() a second time, we ensure that this new process (fork-2) will have a PID outside the bounds of fork-1’s session. Since we are not calling setsid() on the fork-2 process, no new session is being made. In other words, we know that fork-2 is not a session leader and therefore there’s no risk of it acquiring a terminal in the future.
Finally, by killing fork-2’s parent, we know that we’ve created an orphaned process that is adopted by init and can’t reacquire a terminal or be affected by user input.
TLDR: The 2 fork() calls removes any chance of the daemon reacquiring a controlling terminal and helps ensure that the daemon is re-parented onto init.
If the use of the secondary fork() isn’t clear, don’t worry – it’s more to do with handling a potential edge case in the environment than a necessity in a generic daemon implementation.
Wrapping Up
Thanks for checking out this article! If you have any topic requests, please contact me or leave a comment below!
If you’re interested in seeing all installed daemons on your machine, use this command on Linux machines:
service --status-all
Remember daemon names generally end in “d”
Hope you enjoyed this article. If you're interested in more articles, sign up for the newsletter below or follow me on Twitter.